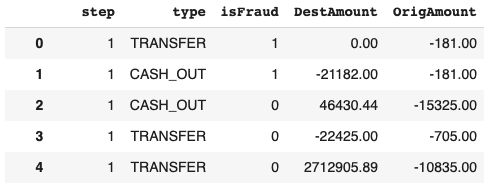
Data Resource: Kaggle
Data Resource: Kaggle

Imbalanced classification involves developing predictive models on classification datasets that have a severe class imbalance. The challenge of working with imbalanced datasets is that most machine learning techniques will ignore, and in turn have poor performance on, the minority class, although typically it is performance on the minority class that is most important. One approach to addressing imbalanced datasets is to oversample the minority class. The simplest approach involves duplicating examples in the minority class, although these examples don’t add any new information to the model. Instead, new examples can be synthesized from the existing examples. This is a type of data augmentation for the minority class and is referred to as the Synthetic Minority Oversampling Technique, or SMOTE for short.
Click for details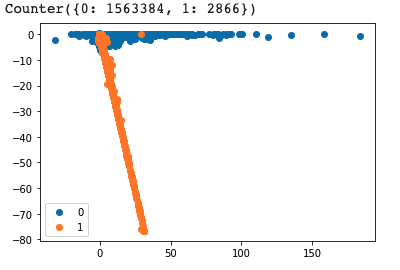
The theory is mature and the idea is simple, which can be used for both classification and regression
It can be used for nonlinear classification
The training time complexity is lower than that of algorithms such as support vector machine
There is no assumption on data, with high accuracy and insensitivity to outliers
Simple implementation, widely used in industrial problems;
The calculation amount is very small, the speed is very fast.
For logistic regression, multicollinearity is not a problem, which can be solved by combining with L2 regularization.
The calculation cost is not high, easy to understand and implement;
Anti-fraud has always been one of the hottest and most challenging projects. Anti-fraud programs often involve clients having no idea what fraud is and what it is not. In other words, the definition of fraud is vague. At a minimum, anti-fraud may seem like a binary classification, but when you think about it, it's actually a multi-class classification because each different type of fraud can be treated as a separate type. A single type of fraud almost does not exist, and the methods of fraud change from day to day. Even industries that deal with fraud for years, such as banks and insurance companies, must constantly update their detection methods.
Based on this data, my method is to simplify the data and get the most related features.Because in the data scient field, more features are not always better.
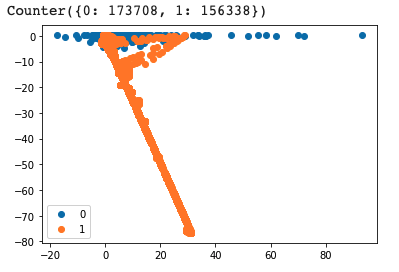
After the pre-processing, I found that the amount changes of original account and destination account ware highly related to the fraud transaction.
I find that there are specific patterns for different types of transactions:
1. CASH-IN: Non-fraud
2. DEBIT: Non-fraud
3. PAYMENT: Non-fraud
4. CASH-OUT: When the amount of the original account decreses and destination account increases, this transaction has high risk to be fraud.
5. TRANSFER: When the amount of the original account decreses and destination account stays still, this transaction has high risk to be fraud.
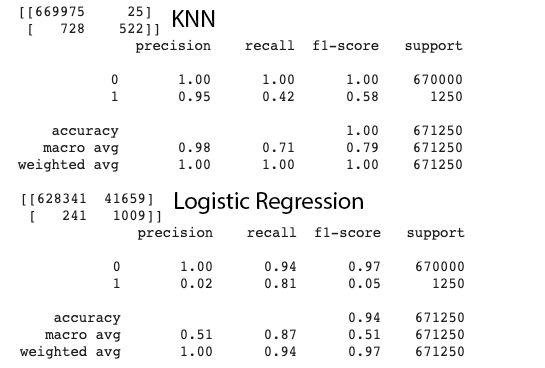
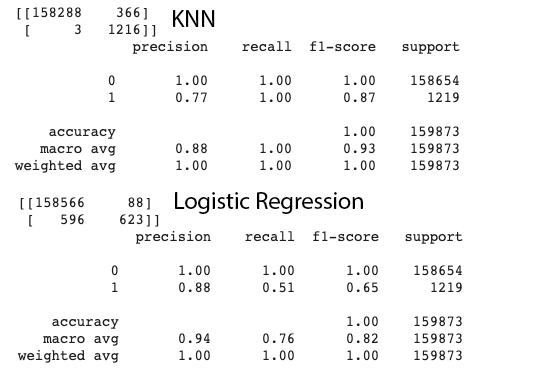
That's why I excluded other transaction types other than CASH-OUT and TRANSFER. And the plots insipred me that KNN should be easily and accurately classify the fraud transactions. And the result showed that I am right.
In the future, if there are more transactions data coming, I will suggest the facility follow the steps to detect the fraud:
1. Only extract the CASH-OUT and the TRANSFER transaction.
2. Apply my trained Logistic Regression model to detect CASH-OUT fraud.
3. Apply my trained KNN model to detect TRANSFER fraud.
If I have enough time, I can try more models, such as XGBoost, Multilayer Perceptron, Decision Tree, Random Forest, etc., and conduct parameter tuning and tuning.
By comparing the Confusion Matrix of multiple models, we can more intuitively choose the optimal model and the optimal solution under different conditions.
Combining different data augmentation and model embedding, we may be able to achieve more direction and better results.
Given enough time, this interface can have more interactive effects, as well as a more concise and beautiful layout.
It may be possible to connect to a trained model so that the user can enter a Feature to verify whether there is a potential fraud risk.
A world adventurer and problem solver. Always be curious about new things and enthusiastic about big challenges. With data as the rope, down-to-earth climb the hills of life.